GraphQL, created by Facebook, is an open-source technology used on servers to make data requests more efficient compared to traditional REST APIs.GraphQL serves a dual purpose: it acts as a language for requesting specific data and as an engine that processes and delivers that data efficiently.
Why use GraphQL?
- Precise Data Fetching: With GraphQL, clients can specify exactly what data they require, minimizing unnecessary data transfer. This improves performance by speeding up responses and saving bandwidth.
- Simplified Data Retrieval: Instead of making multiple API calls to different endpoints—like in REST—GraphQL lets you fetch all related data in just one request, making the process more streamlined.
- Real-Time Data Streaming: GraphQL supports real-time data streaming through subscriptions, allowing servers to push immediate updates to clients the moment any changes occur.
- Clear Structure: GraphQL uses a type-based schema, which clearly defines the available data and how to query it, making APIs more predictable and easier to work with.
Components in GraphQL
- Data Requests (Query): With GraphQL, you can request customized data from the server by defining exactly what information you need. Unlike REST—where each data type has its own endpoint—GraphQL allows you to fetch only the information you need in one go, making requests more flexible and efficient.
- Data Blueprint (Schema): Think of a GraphQL schema as the rulebook for your data. It clearly lays out what kinds of information are available, how they’re connected, and what actions (like fetching or updating data) are possible. Essentially, it tells developers exactly how they can ask for or modify data through the API—keeping everything organized and predictable.
- Response Generator (Resolver): Resolvers are functions that handle GraphQL queries by fetching the requested data. Each resolver takes in specific arguments to process the query and return the correct response.
- Interactive Tool (GraphiQL): GraphiQL is a web-based tool that helps you write, test, and debug GraphQL queries and mutations directly in your browser, making development faster and easier.
Client Server Architecture
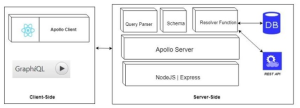
Workflow for the above image:
- Request from the Client: The client application initiates a data request by sending a GraphQL query or mutation to the server using Apollo Client.
- Processing on the Server: Apollo Server receives the request, interprets the query, and checks it against the schema to ensure it’s valid and to identify the requested data.
- Fetching the Data: The server uses resolver functions to gather the necessary information. Resolvers fetch the required information by accessing databases, third-party APIs, or any relevant data source.
- Sending the Response: Once the data is collected, Apollo Server formats it and sends it back to the client.
- Updating the Client: Apollo Client receives the response, stores it in its local cache, and makes the data available to the application—enabling UI updates or further actions.
Code Part: How to Tackle Multiple Data Points?
from flask import Flask
from flask_graphql import GraphQLView
import graphene, requests
class Database:
@staticmethod
def get_user(user_id):
users = {"1": {"id": "1", "name": "John Doe", "email": "john.doe@example.com"}, "2": {"id": "2", "name": "Jane Smith", "email": "jane.smith@example.com"}}
return users.get(user_id)
def fetch_posts(user_id):
posts_url = f"https://jsonplaceholder.typicode.com/posts?userId={user_id}"
response = requests.get(posts_url)
return response.json() if response.status_code == 200 else []
class PostType(graphene.ObjectType):
id = graphene.ID()
title = graphene.String()
body = graphene.String()
class UserType(graphene.ObjectType):
id = graphene.ID()
name = graphene.String()
email = graphene.String()
posts = graphene.List(PostType)
class Query(graphene.ObjectType):
user = graphene.Field(UserType, user_id=graphene.ID(required=True))
def resolve_user(self, info, user_id):
user_data = Database.get_user(user_id)
if user_data:
user_data['posts'] = fetch_posts(user_id)
return user_data
app = Flask(__name__)
app.add_url_rule('/graphql', view_func=GraphQLView.as_view('graphql', schema=graphene.Schema(query=Query), graphiql=True))
if __name__ == '__main__':
app.run(debug=True)
Query for the above code:
query {
user(userId: "1") {
id
name
email
posts {
id
title
body
}
}
}
Response:
{
"data": {
"user": {
"id": "1",
"name": "John Doe",
"email": "john.doe@example.com",
"posts": [
{
"id": "1",
"title": "Post Title 1",
"body": "Post Body 1"
},
{
"id": "2",
"title": "Post Title 2",
"body": "Post Body 2"
}
]
}
}
}
Subscriptions in GraphQL:
GraphQL subscriptions work like a live feed between the client and server. Instead of just asking for data once (like with queries or mutations), they keep the connection alive, so the server can instantly push updates to the client whenever something changes. This is perfect for apps that need to show real-time information, like chat messages or live sports scores.
Real-life use cases of subscriptions in graphQL
- Instant Messaging Apps: Subscriptions power features like real-time message delivery, live typing indicators, and up-to-the-second user status updates, ensuring a seamless chat experience.
- Dynamic Social Platforms:Users receive live updates for new posts, reactions, and comments on their feed, eliminating the need to manually refresh the page.
- Financial Dashboards: Investors and traders benefit from live updates on stock prices, trading activity, and cryptocurrency market changes, keeping them informed without delay.


